| 19 Jul 2018
| 19 Jul 2018
Probabilistic short term wind power forecasts using deep neural networks with discrete target classes
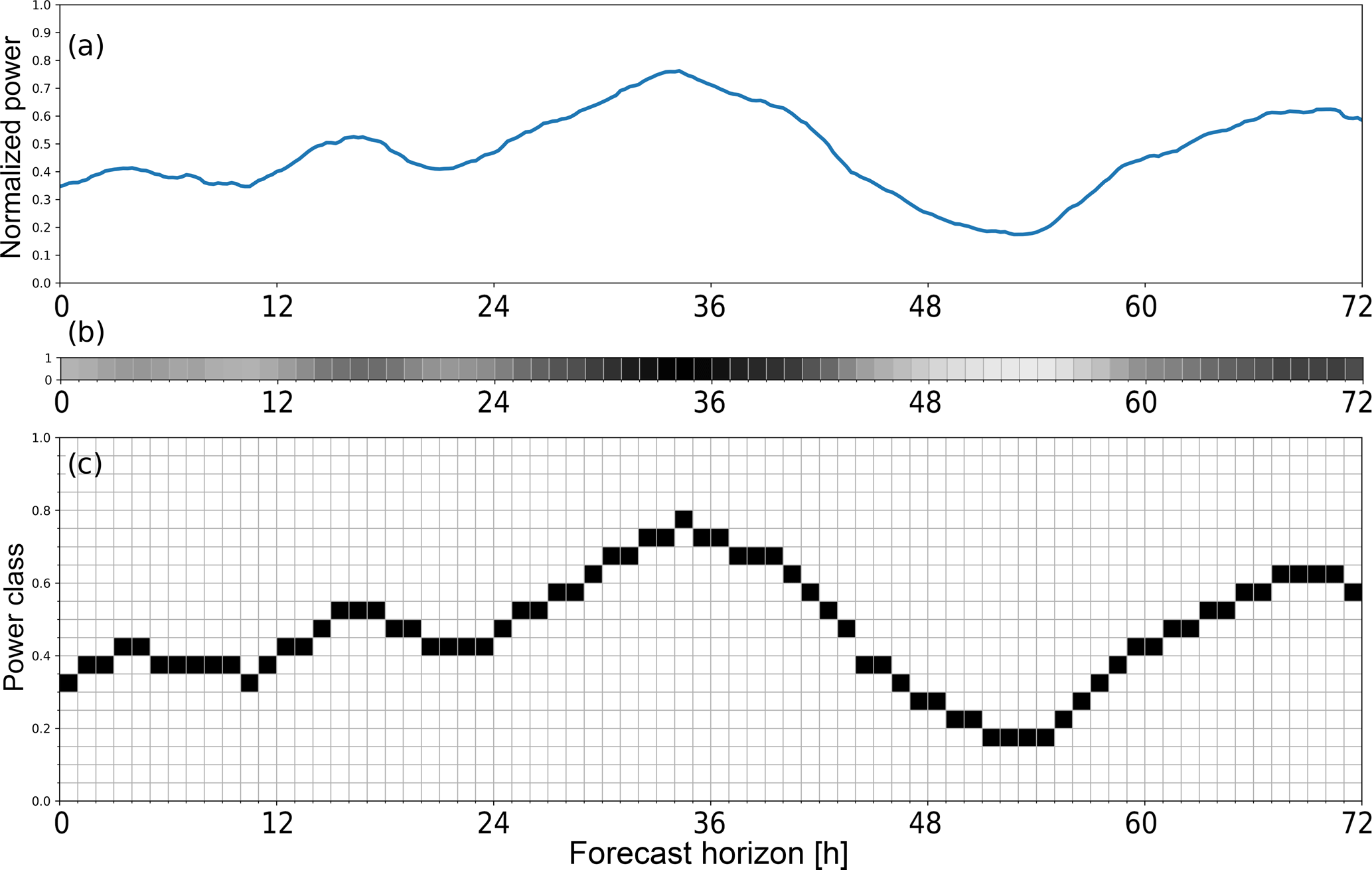
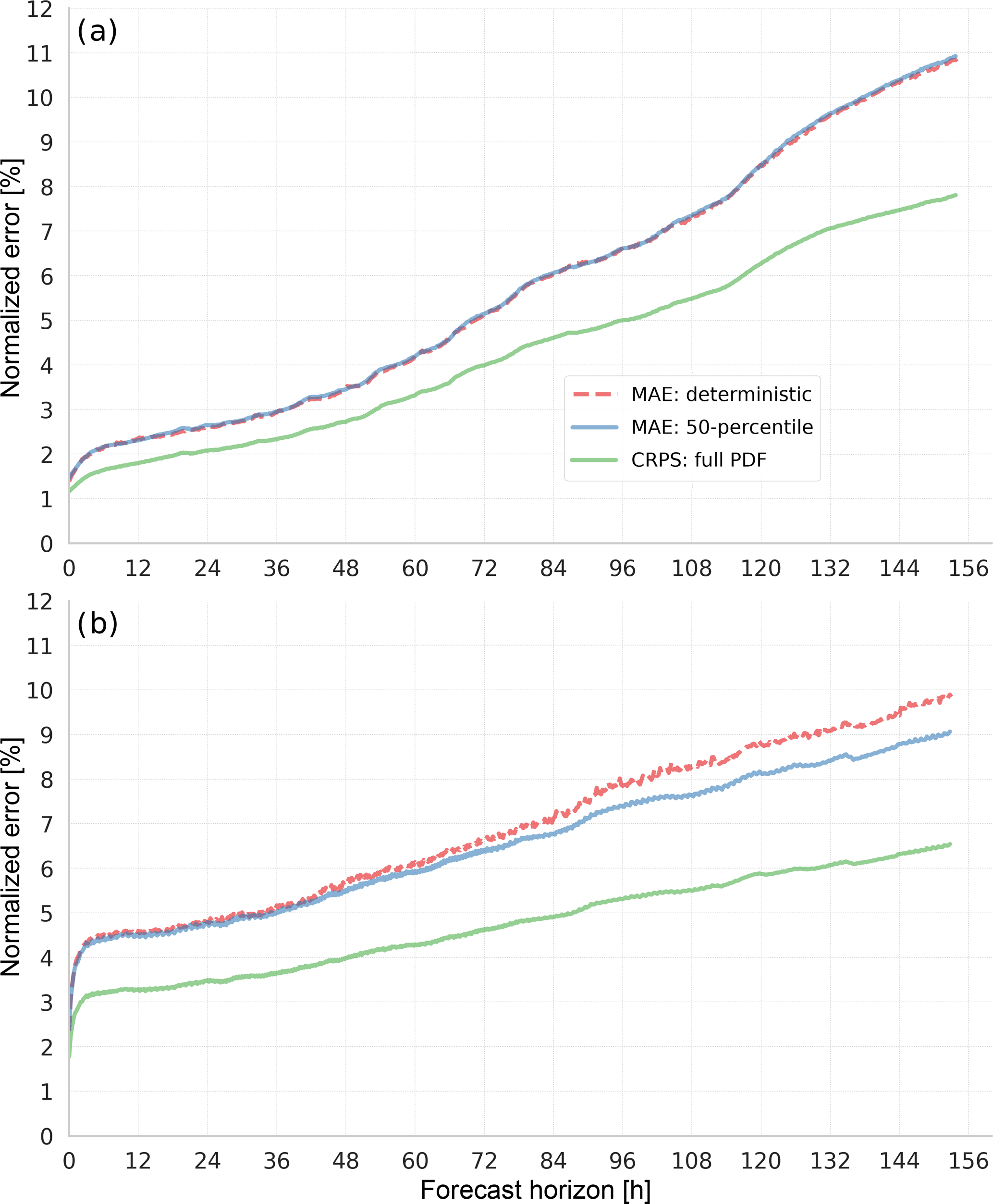
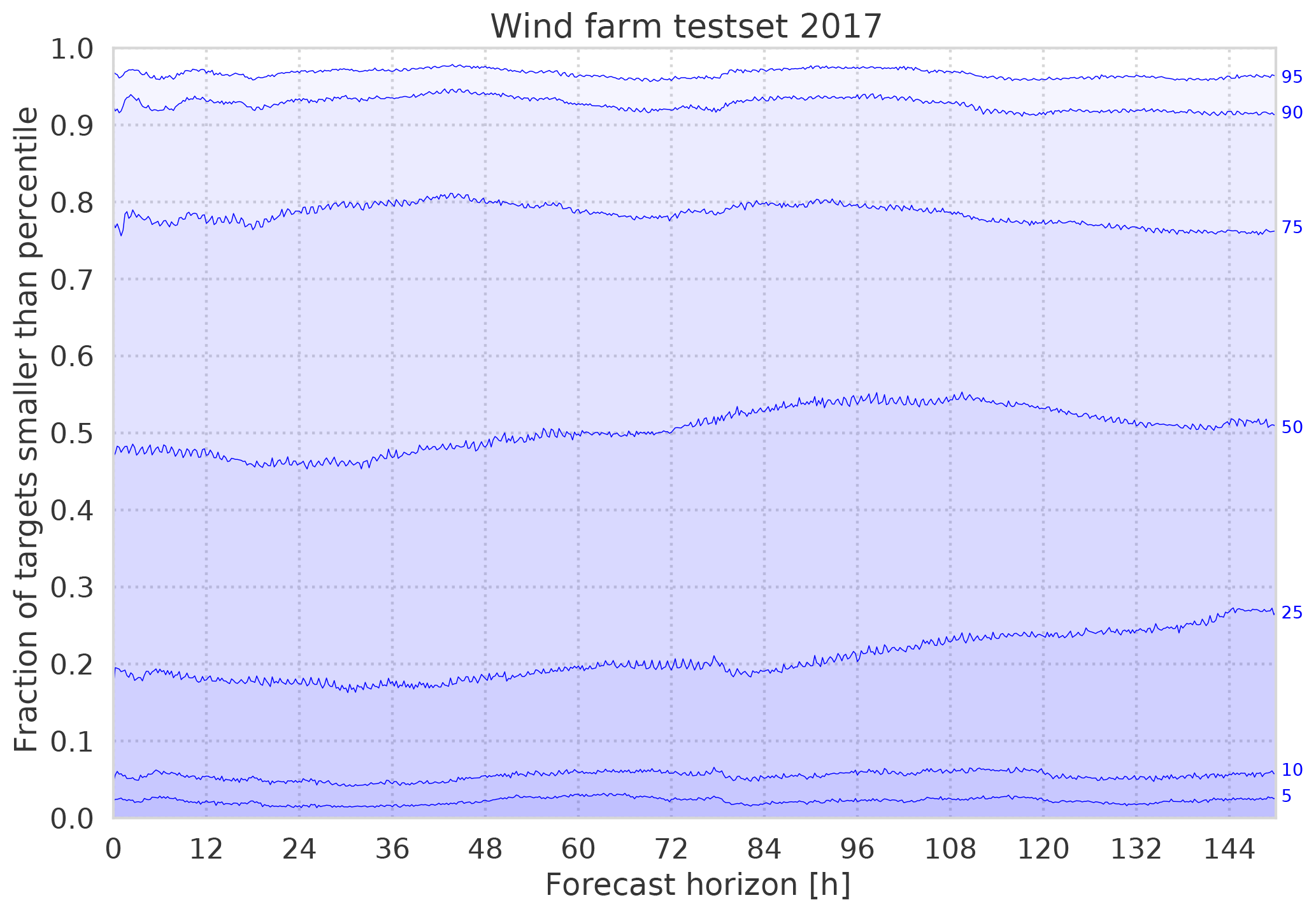
Usually, neural networks trained on historical feed-in time series of wind turbines deterministically predict power output over the next hours to days. Here, the training goal is to minimise a scalar cost function, often the root mean square error (RMSE) between network output and target values. Yet similar to the analog ensemble (AnEn) method, the training algorithm can also be adapted to analyse the uncertainty of the power output from the spread of possible targets found in the historical data for a certain meteorological situation. In this study, the uncertainty estimate is achieved by discretising the continuous time series of power targets into several bins (classes). For each forecast horizon, a neural network then predicts the probability of power output falling into each of the bins, resulting in an empirical probability distribution. Similiar to the AnEn method, the proposed method avoids the use of costly numerical weather prediction (NWP) ensemble runs, although a selection of several deterministic NWP forecasts as input is helpful. Using state-of-the-art deep learning technology, we applied our method to a large region and a single wind farm. MAE scores of the 50-percentile were on par with or better than comparable deterministic forecasts. The corresponding Continuous Ranked Probability Score (CRPS) was even lower. Future work will investigate the overdispersiveness sometimes observed, and extend the method to solar power forecasts.